
分布式事务是企业集成中的一个技术难点,也是每一个分布式系统架构中都会涉及到的一个东西,特别是在这几年越来越火的微服务架构中,几乎可以说是无法避免,本文就围绕分布式事务各方面与大家进行介绍。
事务
1.1 什么是事务
数据库事务(简称:事务,Transaction)是指数据库执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。
事务拥有以下四个特性,习惯上被称为ACID特性:
- 原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
- 一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态是指数据库中的数据应满足完整性约束。除此之外,一致性还有另外一层语义,就是事务的中间状态不能被观察到(这层语义也有说应该属于原子性)。
- 隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行,如同只有这一个操作在被数据库所执行一样。
- 持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中。在事务结束时,此操作将不可逆转。
1.2 本地事务
起初,事务仅限于对单一数据库资源的访问控制:

架构服务化以后,事务的概念延伸到了服务中。倘若将一个单一的服务操作作为一个事务,那么整个服务操作只能涉及一个单一的数据库资源:
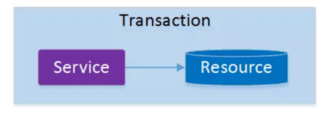
这类基于单个服务单一数据库资源访问的事务,被称为本地事务(Local Transaction)。
分布式事务
本地事务主要限制在单个会话内,不涉及多个数据库资源。但是在基于SOA(Service-Oriented Architecture,面向服务架构)的分布式应用环境下,越来越多的应用要求对多个数据库资源,多个服务的访问都能纳入到同一个事务当中,分布式事务应运而生。
最早的分布式事务应用架构很简单,不涉及服务间的访问调用,仅仅是服务内操作涉及到对多个数据库资源的访问。
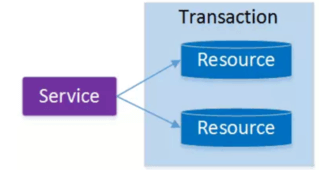
当一个服务操作访问不同的数据库资源,又希望对它们的访问具有事务特性时,就需要采用分布式事务来协调所有的事务参与者。
对于上面介绍的分布式事务应用架构,尽管一个服务操作会访问多个数据库资源,但是毕竟整个事务还是控制在单一服务的内部。如果一个服务操作需要调用另外一个服务,这时的事务就需要跨越多个服务了。在这种情况下,起始于某个服务的事务在调用另外一个服务的时候,需要以某种机制流转到另外一个服务,从而使被调用的服务访问的资源也自动加入到该事务当中来。下图反映了这样一个跨越多个服务的分布式事务:

如果将上面这两种场景(一个服务可以调用多个数据库资源,也可以调用其他服务)结合在一起,对此进行延伸,整个分布式事务的参与者将会组成如下图所示的树形拓扑结构。在一个跨服务的分布式事务中,事务的发起者和提交均系同一个,它可以是整个调用的客户端,也可以是客户端最先调用的那个服务。
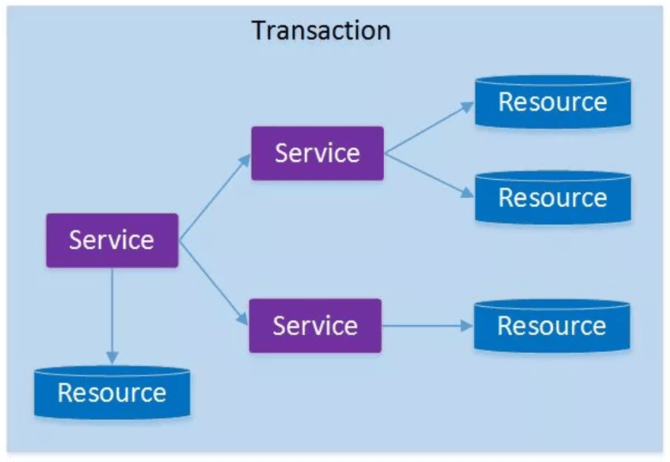
较之基于单一数据库资源访问的本地事务,分布式事务的应用架构更为复杂。
在不同的分布式应用架构下,实现一个分布式事务要考虑的问题并不完全一样,比如对多资源的协调、事务的跨服务传播等,实现机制也是复杂多变。尽管有这么多工程细节需要考虑,但分布式事务最核心的还是其 ACID 特性。因此,想要了解一个分布式事务,就先从了解它是怎么实现事务 ACID 特性开始。
下文将从两个最常见的分布式事务模型入手,着重分析分布式事务的基础共通点,即如何保证分布式事务的 ACID 特性。
常见的分布式事务解决方案
1.基于XA协议的两阶段提交
XA是一个分布式事务协议,由Tuxedo提出。XA中大致分为两部分:事务管理器和本地资源管理器。其中本地资源管理器往往由数据库实现,比如Oracle、DB2这些商业数据库都实现了XA接口,而事务管理器作为全局的调度者,负责各个本地资源的提交和回滚。XA实现分布式事务的原理如下:

总的来说,XA协议比较简单,而且一旦商业数据库实现了XA协议,使用分布式事务的成本也比较低。但是,XA也有致命的缺点,那就是性能不理想,特别是在交易下单链路,往往并发量很高,XA无法满足高并发场景。XA目前在商业数据库支持的比较理想,在mysql数据库中支持的不太理想,mysql的XA实现,没有记录prepare阶段日志,主备切换回导致主库与备库数据不一致。许多nosql也没有支持XA,这让XA的应用场景变得非常狭隘。
2.消息事务 最终一致性
所谓的消息事务就是基于消息中间件的两阶段提交,本质上是对消息中间件的一种特殊利用,它是将本地事务和发消息放在了一个分布式事务里,保证要么本地操作成功成功并且对外发消息成功,要么两者都失败,开源的RocketMQ就支持这一特性,具体原理如下:
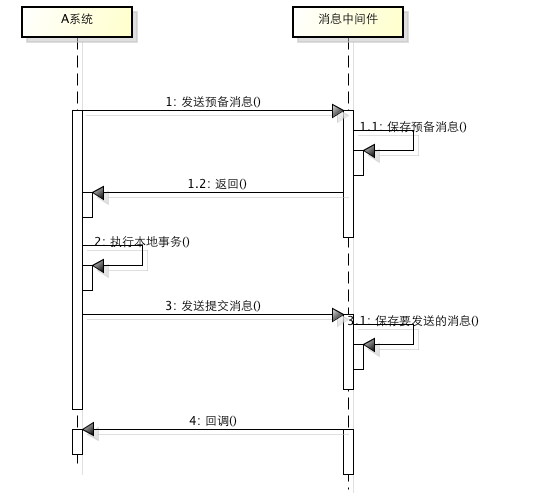
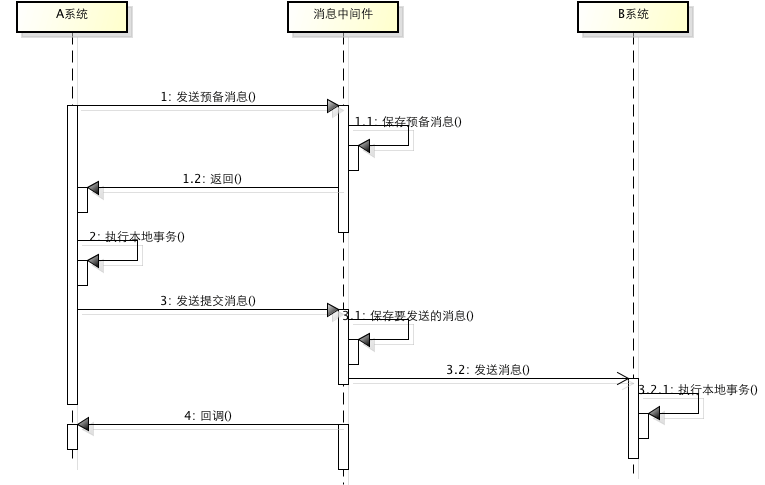
1、A系统向消息中间件发送一条预备消息
2、消息中间件保存预备消息并返回成功
3、A执行本地事务
4、A发送提交消息给消息中间件
通过以上4步完成了一个消息事务。对于以上的4个步骤,每个步骤都可能产生错误,下面一一分析:
- 步骤一出错,则整个事务失败,不会执行A的本地操作
- 步骤二出错,则整个事务失败,不会执行A的本地操作
- 步骤三出错,这时候需要回滚预备消息,怎么回滚?答案是A系统实现一个消息中间件的回调接口,消息中间件会去不断执行回调接口,检查A事务执行是否执行成功,如果失败则回滚预备消息
- 步骤四出错,这时候A的本地事务是成功的,那么消息中间件要回滚A吗?答案是不需要,其实通过回调接口,消息中间件能够检查到A执行成功了,这时候其实不需要A发提交消息了,消息中间件可以自己对消息进行提交,从而完成整个消息事务
基于消息中间件的两阶段提交往往用在高并发场景下,将一个分布式事务拆成一个消息事务(A系统的本地操作 发消息) B系统的本地操作,其中B系统的操作由消息驱动,只要消息事务成功,那么A操作一定成功,消息也一定发出来了,这时候B会收到消息去执行本地操作,如果本地操作失败,消息会重投,直到B操作成功,这样就变相地实现了A与B的分布式事务。原理如下:
虽然上面的方案能够完成A和B的操作,但是A和B并不是严格一致的,而是最终一致的,我们在这里牺牲了一致性,换来了性能的大幅度提升。当然,这种玩法也是有风险的,如果B一直执行不成功,那么一致性会被破坏,具体要不要玩,还是得看业务能够承担多少风险。
3.TCC 模型
TCC(Try-Confirm-Cancel)分布式事务模型相对于 XA 等传统模型,其特征在于它不依赖资源管理器(RM)对分布式事务的支持,而是通过对业务逻辑的分解来实现分布式事务。
TCC 模型认为对于业务系统中一个特定的业务逻辑,其对外提供服务时,必须接受一些不确定性,即对业务逻辑初步操作的调用仅是一个临时性操作,调用它的主业务服务保留了后续的取消权。如果主业务服务认为全局事务应该回滚,它会要求取消之前的临时性操作,这就对应从业务服务的取消操作。而当主业务服务认为全局事务应该提交时,它会放弃之前临时性操作的取消权,这对应从业务服务的确认操作。每一个初步操作,最终都会被确认或取消。
因此,针对一个具体的业务服务,TCC 分布式事务模型需要业务系统提供三段业务逻辑:
初步操作 Try:完成所有业务检查,预留必须的业务资源。
确认操作 Confirm:真正执行的业务逻辑,不作任何业务检查,只使用 Try 阶段预留的业务资源。因此,只要 Try 操作成功,Confirm 必须能成功。另外,Confirm 操作需满足幂等性,保证一笔分布式事务有且只能成功一次。
取消操作 Cancel:释放 Try 阶段预留的业务资源。同样的,Cancel 操作也需要满足幂等性。
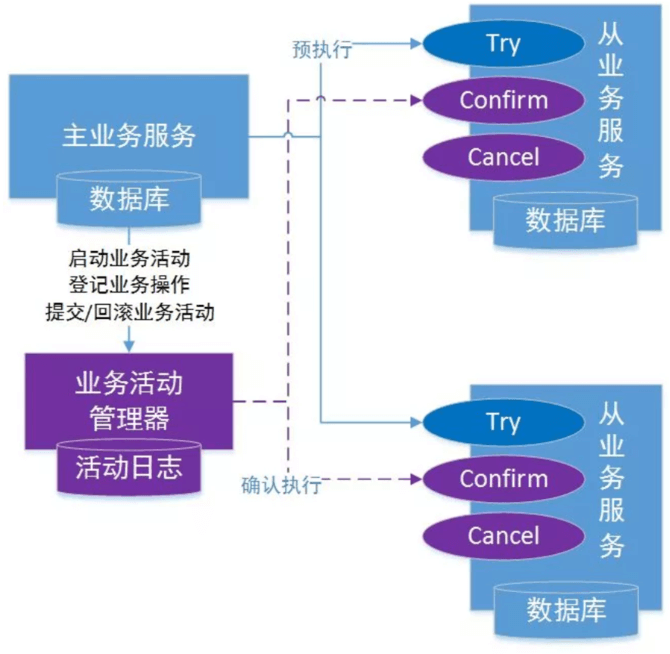
TCC 分布式事务模型包括三部分:
1.主业务服务:主业务服务为整个业务活动的发起方,服务的编排者,负责发起并完成整个业务活动。
2.从业务服务:从业务服务是整个业务活动的参与方,负责提供 TCC 业务操作,实现初步操作(Try)、确认操作(Confirm)、取消操作(Cancel)三个接口,供主业务服务调用。
3.业务活动管理器:业务活动管理器管理控制整个业务活动,包括记录维护 TCC 全局事务的事务状态和每个从业务服务的子事务状态,并在业务活动提交时调用所有从业务服务的 Confirm 操作,在业务活动取消时调用所有从业务服务的 Cancel 操作。
一个完整的 TCC 分布式事务流程如下:
- 主业务服务首先开启本地事务;
- 主业务服务向业务活动管理器申请启动分布式事务主业务活动;
- 然后针对要调用的从业务服务,主业务活动先向业务活动管理器注册从业务活动,然后调用从业务服务的 Try 接口;
- 当所有从业务服务的 Try 接口调用成功,主业务服务提交本地事务;若调用失败,主业务服务回滚本地事务;
- 若主业务服务提交本地事务,则 TCC 模型分别调用所有从业务服务的 Confirm 接口;若主业务服务回滚本地事务,则分别调用 Cancel 接口;
- 所有从业务服务的 Confirm 或 Cancel 操作完成后,全局事务结束。
TCC模型小结
所谓的TCC编程模式,也是两阶段提交的一个变种。TCC提供了一个编程框架,将整个业务逻辑分为三块:Try、Confirm和Cancel三个操作。以在线下单为例,Try阶段会去扣库存,Confirm阶段则是去更新订单状态,如果更新订单失败,则进入Cancel阶段,会去恢复库存。总之,TCC就是通过代码人为实现了两阶段提交,不同的业务场景所写的代码都不一样,复杂度也不一样,因此,这种模式并不能很好地被复用。
分布式事务总结
分布式事务,本质上是对多个数据库的事务进行统一控制,按照控制力度可以分为:不控制、部分控制和完全控制。不控制就是不引入分布式事务,部分控制就是各种变种的两阶段提交,包括上面提到的消息事务 最终一致性、TCC模式,而完全控制就是完全实现两阶段提交。部分控制的好处是并发量和性能很好,缺点是数据一致性减弱了,完全控制则是牺牲了性能,保障了一致性,具体用哪种方式,最终还是取决于业务场景。作为技术人员,一定不能忘了技术是为业务服务的,不要为了技术而技术,针对不同业务进行技术选型也是一种很重要的能力!
作者简介
陈睿|mikechen,10年+大厂架构经验,BAT资深面试官,就职于阿里巴巴、淘宝、百度等一线互联网大厂。
关注作者「mikechen」公众号,获取更多技术干货!

后台回复【架构】,即可获取《阿里架构师进阶专题全部合集》,后台回复【面试】即可获取《史上最全阿里Java面试题总结》
收藏了!