

数据拆分前其实是要首先做准备工作的,然后才是开始数据拆分,我先讲拆分前需要做的事情:
- 第一步:采用分布式缓存redis、memcached等降低对数据库的读操作。
- 第二步:如果缓存使用过后,数据库访问量还是非常大,可以考虑数据库读、写分离原则。
- 第三步:当我们使用读写分离、缓存后,数据库的压力还是很大的时候,这就需要使用到数据库拆分了。
数据库拆分原则:就是指通过某种特定的条件,按照某个维度,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)上面以达到分散单库(主机)负载的效果。
第一步,首选垂直拆分
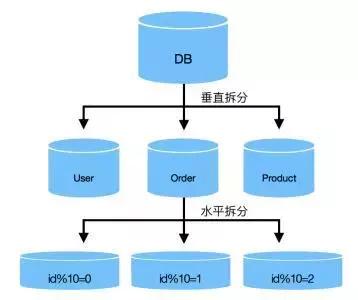
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同的数据库上面,这样也就将数据或者说压力分担到不同的库上面 。
比如淘宝中期开始的数据库端按照业务垂直拆分:按照业务交易数据库、用户数据库、商品数据库、店铺数据库等进行拆分。
采用垂直拆分
优点:
1. 拆分后业务清晰,拆分规则明确。
2. 系统之间整合或扩展容易。
3. 数据维护简单。
缺点:
1. 部分业务表无法join,只能通过接口方式解决,提高了系统复杂度。
2. 受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高。
3. 事务处理复杂。
第二步:其次才是水平拆分
水平拆分的典型场景就是大家熟知的分库分表。
垂直拆分后遇到单机瓶颈,可以使用水平拆分。相对于垂直拆分的区别是:垂直拆分是把不同的表拆到不同的数据库中,而水平拆分是把同一个表拆到不同的数据库中。
相对于垂直拆分,水平拆分不是将表的数据做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中 的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中。
分库分表需要涉及到对应的SQL路由规则主库备库等,例如:淘宝设计了一套TDDL来解决这些问题,应用端只需配置对应的规则即可,对应用端的没有任何侵入的设计。
水平拆分,总之,一般先分库,如果分库后查询仍然慢,于是按照分库的思想开始做分表的工作数据库采用分布式数据库(所有节点的数据加起来才算是整体数据),文件系统采用分布式文件系统任何强大的单一服务器都满足不了大型系统持续增长的业务需求,数据库读写分离随着业务的发展最终也将无法满足需求,需要使用分布式数据库及分布式文件系统来支撑。
总结,数据库拆分原则:
1.优先考虑缓存降低对数据库的读操作。
2.再考虑读写分离,降低数据库写操作。
3.最后开始数据拆分,切分模式: 首先垂直(纵向)拆分、再次水平拆分。
4.首先考虑按照业务垂直拆分。
5.再考虑水平拆分:先分库(设置数据路由规则,把数据分配到不同的库中)
6.最后再考虑分表,单表拆分到数据1000万以内。
作者简介
陈睿|mikechen,10年+大厂架构经验,BAT资深面试官,就职于阿里巴巴、淘宝、百度等一线互联网大厂。
关注作者「mikechen」公众号,获取更多技术干货!

后台回复【架构】,即可获取《阿里架构师进阶专题全部合集》,后台回复【面试】即可获取《史上最全阿里Java面试题总结》
无意中看到一篇文章吸引过来了,写的都很不错,值得学习