

从Java程序员到架构师进阶,将涉及到数据结构和算法,Java编程语言掌握,Javaweb核心技术,数据库,Java框架与必备工具,系统架构设计等六大环节。
编程基础:数据结构和算法
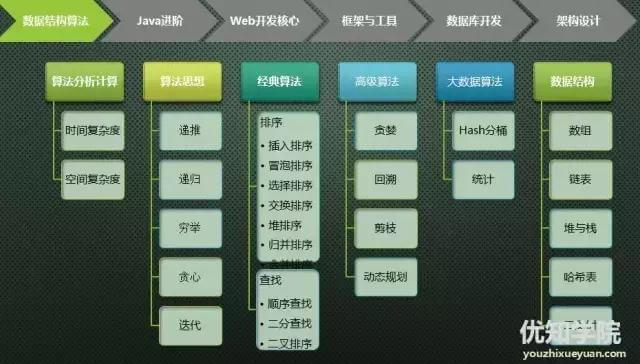
1 算法分析与计算
算法时间复杂度和空间复杂度的分析计算
2.算法思想
递推、递归、穷举、贪心、分治、动态规划、迭代、分枝界限
3常用数据结构
数组、链表、堆、栈、队列、Hash表、二叉树等
4经典算法
排序
经典排序:插入排序、冒泡排序、快排(分划交换排序)、直接选择排序、堆排序、合并排序等
查找
经典查找:顺序查找、二分查找、二叉排序树查找
java语言掌握
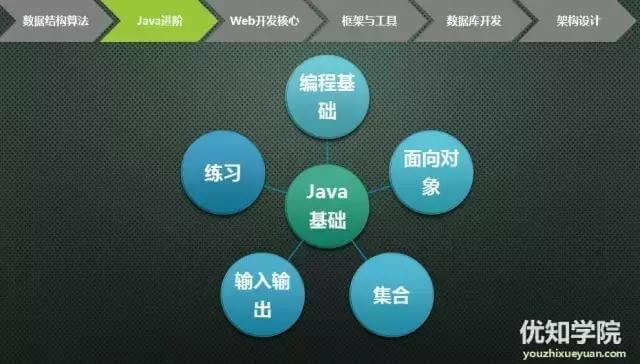
Java语言基础
Java语法格式,常量和变量,变量的作用域,方法和方法的重载,运算符,程序流程控制,各种基本数据类型及包装类
2面向对象基础
面向对象编程思想,类与对象,成员变量和局部变量,封装,this关键字,final关键字,static关键字。
3 常用集合使用
Collection以及各种List、Set、Queue、Map的实现以及集成关系,实现原理。
ArrayList,HashMap等常用集合优劣比较。
Java语言高级


1.面向对象高级
对象的三大特性:封装、继承和多态,优缺点
如何设计类,类的设计原则。
构造函数,内部类,抽象类,接口,对象的多态性,接口和抽象类的区别。
2.异常处理
Throwable/Error/Exception,Checked Exception vs. Unchecked Exception,异常的捕捉和抛出,异常捕捉的原则,finally的使用
3.多线程
创建与启动
线程和进程的概念
如何在程序中创建多线程,线程安全问题,线程之间的通讯
线程的同步与锁
死锁问题的剖析
线程生命周期
线程池
4.输入与输出
java.io包,理解IO体系的基于管道模型的设计思路以及常用IO类的特性和使用场合。
File及相关类,字节流InputStream和OutputStream,字符流Reader和Writer,以及相应缓冲流和管道流,字节和字符的转化流,包装流,以及常用包装类使用
分析IO性能
5.反射
类加载机制原理
反射构造方法、字段、方法
Properties配置文件
代理、泛型、枚举、Java正则表达式等
6.网络编程
网络机制
Socket原理机制
UDP、TCP传输等
7.JVM深入理解
一定要深入理解JVM原理,JVM内存划分、class加载机制以及GC策略等。
内存划分,Young Generation(年轻代)、Old Generation(年老代)以及Perm Generation(永久代)。
java web 核心技术


1.前段技术
html、css语法
css需要学习原生态,对css继承等掌握
js原生语法,js原生继承等的掌握
jquery
bootstrap
2.Java Web
建议把java web从容器启动到request、filter、listener了解原理,最好的方法就是通过调试代码一层层断点进入了解源码。
3.模板引擎
常见的模板引擎的语法掌握以及源码查看
4.其他
高性能
安全
事务JTA
其他需要了解的,如:管理JMX、安全JCCA/JAAS、集成JCA、通信JNDI/JMS/JavaMain/JAF、SSI技术。
数据库设计原则和大数据方案

谈到数据库将涉及到如下范围:
数据库设计原则和范式
第一范式,确保每列保持原子性。
第二范式,确保表中的每列都和主键相关。
第二范式,在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
第三范式,确保每列都和主键列直接相关,而不是间接相关。
比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。
SQL与NoSql的优缺点以及使用场景分析
SQL (Structured Query Language) 数据库,指关系型数据库 – 主要代表:SQL Server,Oracle,MySQL(开源),PostgreSQL(开源)。
NoSQL(Not Only SQL)泛指非关系型数据库 -。主要代表:MongoDB,Redis,Memcached,Hbase,CouchDB。
目前许多大型互联网项目都会选用MySQL(或任何关系型数据库) NoSQL的组合方案。
关系型数据库适合存储结构化数据,如用户的帐号、地址:
1)这些数据通常需要做结构化查询,比如join,这时候,关系型数据库就要胜出一筹
2)这些数据的规模、增长的速度通常是可以预期的
3)事务性、一致性
NoSQL适合存储非结构化数据,如文章、评论:
1)这些数据通常用于模糊处理,如全文搜索、机器学习
2)这些数据是海量的,而且增长的速度是难以预期的
3)根据数据的特点,NoSQL数据库通常具有无限(至少接近)伸缩性
4)按key获取数据效率很高,但是对join或其他结构化查询的支持就比较差
关系式数据库必备
事务(ACID、工作原理、事务的隔离级别、锁、事务的传播机制)
数据库创建,权限分配,表的创建,增删改查,连接,子查询
索引
数据库索引好比是一本书前面的目录,能加快数据库的查询速度。索引分为聚簇索引和非聚簇索引两种,聚簇索引 是按照数据存放的物理位置为顺序的,而非聚簇索引就不一样了;聚簇索引能提高多行检索的速度,而非聚簇索引对于单行的检索很快。
还有触发器、存储过程、事务控制等
数据库性能优化
索引原理及适用,大表查询优化,多表连接查询优化,子查询优化等
大数据方案
分库、分表、备份、迁移
导入,冷备热备,主从备份、双机热备、纵向扩展、横向扩展等这些都是属于比较常见的数据库方案,我在之前的文章淘宝具体挑战性的一次架构演变中,谈到了数据库纵向和横向的发展策略,里面有详细的方案。
java相关的框架与必备工具
web开发框架
Struts2,SpringMVC,spring(IoC、AOP等)
持久化:hibernate/MyBatis
推荐SSM组合(springMVC Sping Mybatis)
在搭建日志:Log4j,以及单元测试:JUnit
构建工具
Maven Nexus,推荐自己动手搭建一套nexus以及配置maven
模板引擎
Velocity、FreeMaker等
消息队列
ActiveMQ、RabbitMQ等
负载均衡
Nginx/HaProxy
Web服务器
Tomcat、JBoss、Jetty、Resin、WebLogic、WebSphere等
推荐在eclipse里集成run-jetty-run插件,可以在开发环境实行热部署,高效开发必备
java常用通信协议以及比较
RMI,Hessian,Burlap,Httpinvoker,WebService(cxf的soap、restful协议)
分布式缓存
Redis、Memcached等,缓存在大型网站的架构中也是重中之重,特别是分布式缓存和分布式文件存储系统,起着了天然数据库端的防线作用。
分布式文件存储和大数据
常见的分布式文件系统有,GFS、HDFS、Lustre 、Ceph 、GridFS 、mogileFS、TFS、FastDFS等。
GFS(Google File System)
Google公司为了满足本公司需求而开发的基于Linux的专有分布式文件系统。。尽管Google公布了该系统的一些技术细节,但Google并没有将该系统的软件部分作为开源软件发布。
下面分布式文件系统都是类 GFS的产品。
HDFS(Hadoop Distributed File System)
Hadoop 实现了一个分布式文件系统,简称HDFS。 Hadoop是Apache Lucene创始人Doug Cutting开发的使用广泛的文本搜索库。它起源于Apache Nutch,后者是一个开源的网络搜索引擎,本身也是Luene项目的一部分。Aapche Hadoop架构是MapReduce算法的一种开源应用,是Google开创其帝国的重要基石。
TFS(Taobao File System)
TFS是淘宝针对海量非结构化数据存储设计的分布式系统,构筑在普通的Linux机器集群上,可为外部提供高可靠和高并发的存储访问,最初了为了解决淘宝大量小文件的存储早期限制在1M内,现在已经加入大文件的存储。淘宝的TFS其实本身就是从GFS借鉴而来,所以名字也很像。
大型网站架构设计能力
其实就是要很清楚整个技术架构的演变历程,知道每个阶段的瓶颈在哪里,以及对应的解决方案。
随着互联网技术迅速发展和演变,不断改变的商业化应用系统越来越复杂,由单一的应用架构到垂直的应用架构,但还是面临的扩容的问题。流量分散在各个系统中,虽然体积可控,但对开发人员和维护人员带来极麻烦。此时,将核心的业务单独提炼出来作为单独的系统对外提供服务。达成业务之间复用,系统也将演变成分布式系统架构。分布式架构是各组件分布在网络计算机上、组件之间仅仅通过消息传递来通信并协调行动,与上面提到的SOA服务架构一脉相承。
大型网站最终都会走向大型分布式业务场景
搭建分布系统的基础设施
缓存搭建
分布式缓存搭建 memcached ,redis(推荐),动态、静态数据的缓存,以及配合单点登录的使用等。
CDN搭建
为了应付复杂的网络环境和不同地区用户的访问,通过CDN和反向代理加快用户访问的速度,同时减轻后端服务器的负载压力。CDN与反向代理的基本原理都是缓存。
持久化储存搭建
Hbase、MySQL、Redis传统的IOE方案: IBM小型机Oracle数据库 EMC持久储存成本很高。传统的数据库提供完整地acid功能,并且提供丰富的内连接外连接关联查询等功能。但是,对于高并发应用来说,有的时候会牺牲关联查询事务数据一致性(降级为最终一致性)。
Hbase有更好地伸缩能力,更适合海量数据储存。并发写入十分出色,能够支持多regionserver同时写入。但是其本身对于查询的支持力度有限,比如group by order by join等。
Redis是一个key-value类型的数据库,能够支持更高的并发量,而且支持的数据类型也比其他的key-value数据库的数据类型多。
消息系统搭建
目前使用较多的消息队列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ。
使用场景也是非常多:异步处理,应用解耦,流量削锋和消息通讯四个场景。
还有搜索引擎系统、文件系统、日志系统、数据仓库等。
分布式文件系统和分布式数据库
一般先分库,如果分库后查询仍然慢,于是按照分库的思想开始做分表的工作数据库采用分布式数据库(所有节点的数据加起来才算是整体数据),文件系统采用分布式文件系统任何强大的单一服务器都满足不了大型系统持续增长的业务需求,数据库读写分离随着业务的发展最终也将无法满足需求,需要使用分布式数据库及分布式文件系统来支撑。
分布式数据库是系统数据库拆分的最后方法,只有在单表数据规模非常庞大的时候才使用,更常用的数据库拆分手段是业务分库,将不同的业务数据库部署在不同的物理服务器上。
比如淘宝中期开始的数据库端按照业务垂直拆分:按照业务交易数据库、用户数据库、商品数据库、店铺数据库等进行拆分。
还有就是水平扩展,分库分表,再结合读写分离一起。当然,分库分表需要涉及到对应的SQL路由规则主库备库等,淘宝设计了一套TDDL来解决这些问题,应用端只需配置对应的规则即可,对应用端的没有任何侵入的设计。
采用sql和nosql混搭搭建
随着业务越来越复杂,对数据存储和检索的需求也越来越复杂,系统需要采用一些非关系型数据库如NoSQL和分数据库查询技术如搜索引擎。应用服务器通过统一数据访问模块访问各种数据,减轻应用程序管理诸多数据源的麻烦。
代码业务拆分
纵向拆分:
将一个大应用拆分为多个小应用,如果新业务较为独立,那么就直接将其设计部署为一个独立的Web应用系统、纵向拆分相对较为简单,通过梳理业务,将较少相关的业务剥离即可。
横向拆分:
将复用的业务拆分出来,独立部署为分布式服务,新增业务只需要调用这些分布式服务、横向拆分需要识别可复用的业务,设计服务接口,规范服务依赖关系。
还要考虑机房容灾以及系统运维监控等。
作者简介
陈睿|mikechen,10年+大厂架构经验,BAT资深面试官,就职于阿里巴巴、淘宝、百度等一线互联网大厂。
关注作者「mikechen」公众号,获取更多技术干货!

后台回复【架构】,即可获取《阿里架构师进阶专题全部合集》,后台回复【面试】即可获取《史上最全阿里Java面试题总结》
[…] 我已经写过了一篇,java相关的必掌握的高级知识,里面更详尽,从程序员进阶到架构师,史上最全进阶详解(上篇) […]
[…] 1-5的技能能力:程序设计和开发、java web、数据库的技能要求请参考我写的这篇文章:java程序员学习完整线路以及我的学习经验! […]