
分布式是大型架构核心,下面我详解分布式缓存雪崩@mikechen
什么是缓存雪崩
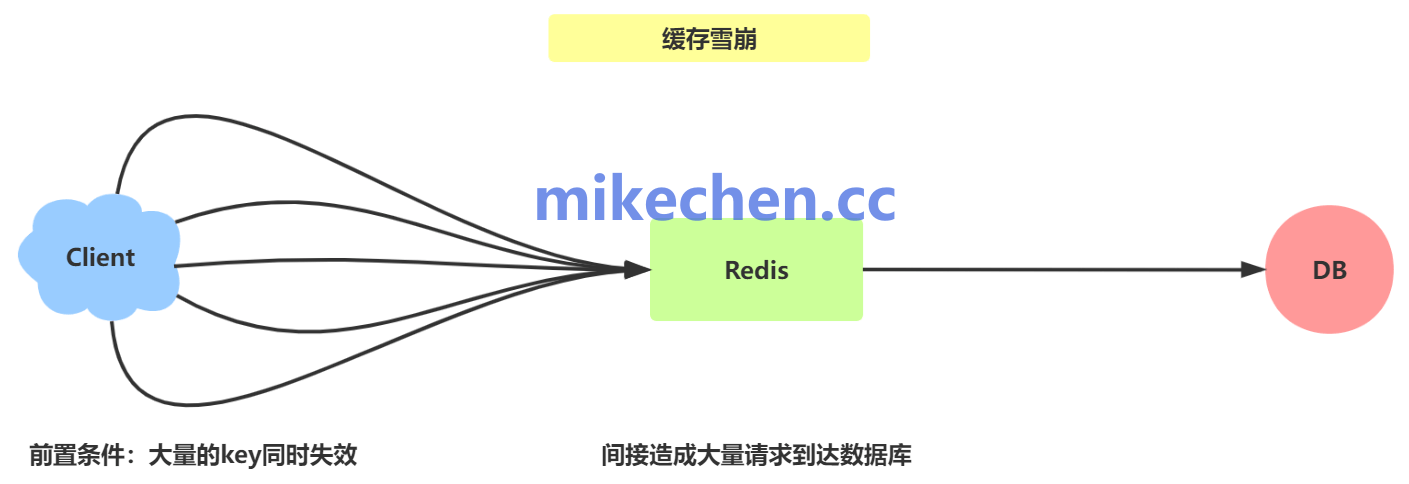
缓存雪崩(Cache Avalanche),是分布式缓存系统(如Redis、Memcached)中一种常见的高并发故障现象。
它指的是缓存层中大量(甚至全部)键值对在同一时间点或极短时间内同时失效(过期、被驱逐或清空)。
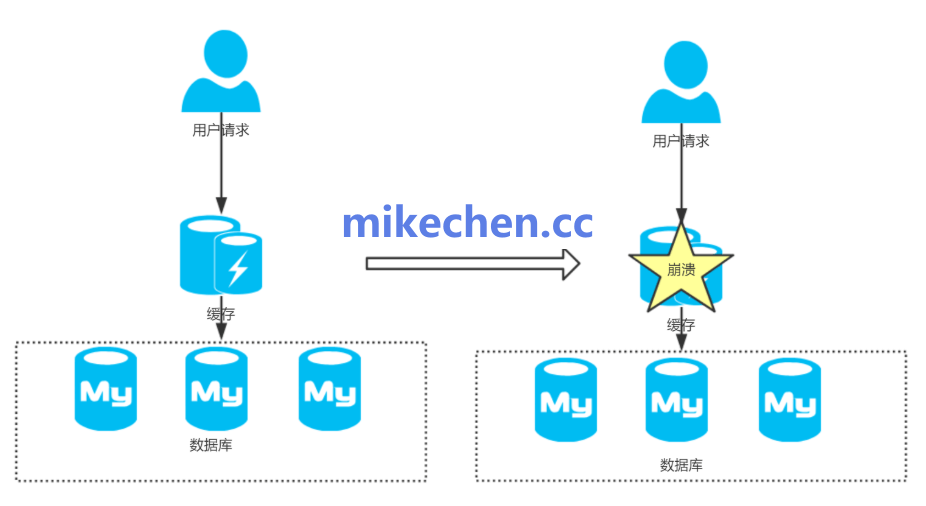
导致后续海量请求无法命中缓存,直接“穿透”到后端数据源(如数据库、搜索引擎)。
这会引发数据源瞬间负载暴增、连接池耗尽,甚至系统级崩溃,形成连锁“雪崩”效应。
为什么会发生缓存雪崩
缓存雪崩并非随机事件,而是由设计、运维或外部因素累积引发。
主要原因包括:统一过期策略:缓存键设置相同的TTL(Time To Live,生存时间)。
如所有键统一1小时后过期,导致批量失效峰值。
缓存资源不足:集群容量有限,高并发填充后触发淘汰算法(如LRU、LFU),热点数据被集体移除。
突发事件或故障:系统重启、清空缓存、流量峰值(如促销开始)。
网络分区或硬件宕机,导致整个缓存层不可用。
缓存雪崩解决方案
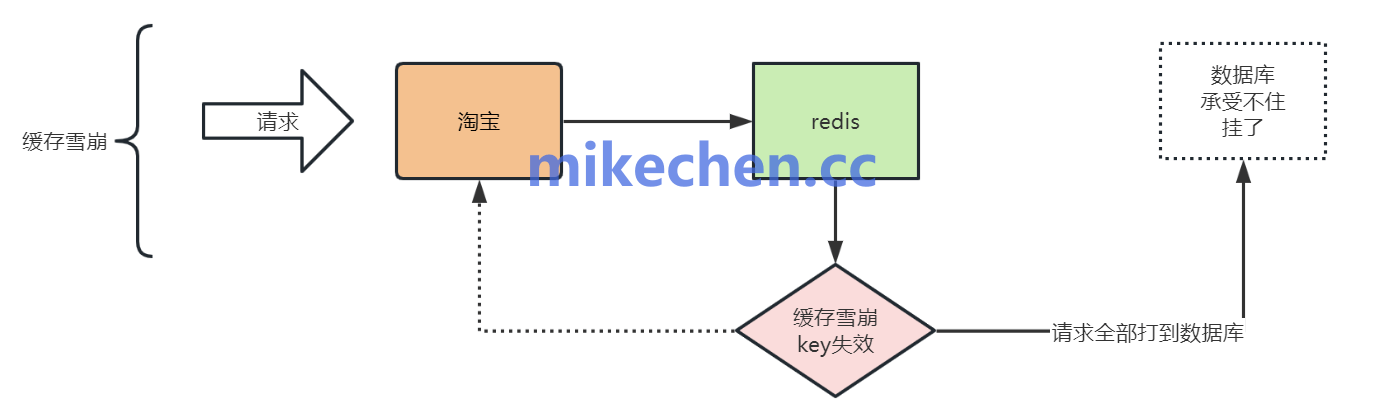
1.缓存过期时间打散(TTL 随机化)
通过为缓存条目,设置不同的过期时间或在原有过期时间上增加随机偏移,避免大量键在同一时刻同时失效。
此方法简单易行,能有效将失效请求分散到较长时间窗口内,从而降低瞬时并发量对后端的冲击。
2.请求限流与熔断
在服务端或网关层对来自客户端的请求进行限流,当请求速率超过阈值时采取降级或丢弃策略,防止后端被瞬时高并发压垮。
结合熔断机制,可以在后端压力过大或出现错误率上升时短暂拒绝或降级请求,待系统恢复后再逐步放量。
该方案适用于突发流量场景,但需谨慎设置阈值以兼顾可用性与容错性。
3.互斥或队列化重建缓存(缓存重建单线程/互斥锁)
当缓存失效时,允许只有一个请求去加载后端数据并重建缓存。
其他请求等待或返回旧值,从而避免大量并发回源。实现方式包括分布式锁、内存互斥或请求排队(如使用队列或信号量)。
此方案能显著降低短时间内的数据库访问量,但需处理好锁失效、锁竞争和等待超时等问题,以免引入新的可用风险。
4.预热与主动刷新
在高峰或部署更新前,主动将热门数据预先加载到缓存,避免在流量到来时出现集中回源。
同时对热点数据采用定期刷新或后台异步刷新策略,确保缓存长期有效且不会在同一时间集中失效。
预热和主动刷新需要结合业务访问热度和部署节奏,合理安排刷新时机与并发策略。
作者简介
陈睿|mikechen,10年+大厂架构经验,BAT资深面试官,就职于阿里巴巴、淘宝、百度等一线互联网大厂。
关注作者「mikechen」公众号,获取更多技术干货!

后台回复【架构】,即可获取《阿里架构师进阶专题全部合集》,后台回复【面试】即可获取《史上最全阿里Java面试题总结》